Move from blogtalkradio to transistor
The podcast host BlogTalkRadio is shutting down effective January 31, 2025.
One of my colleagues has a podcast on that site, so he asked me to help him save his podcasts from being lost to the world.
When you move podcast hosts, it’s not difficult, but some hosting companies make it difficult, which is really a shame.
It should be easy to move.
I’ll document and update things here.
There are a few things that are essential to move to another podcast host.
- Bring in old episodes
- Set up a redirect on the old host site.
Honestly, that’s it. It doesn’t take much.
With just a few months of planning time, before the shut down in January, you need to move quickly.
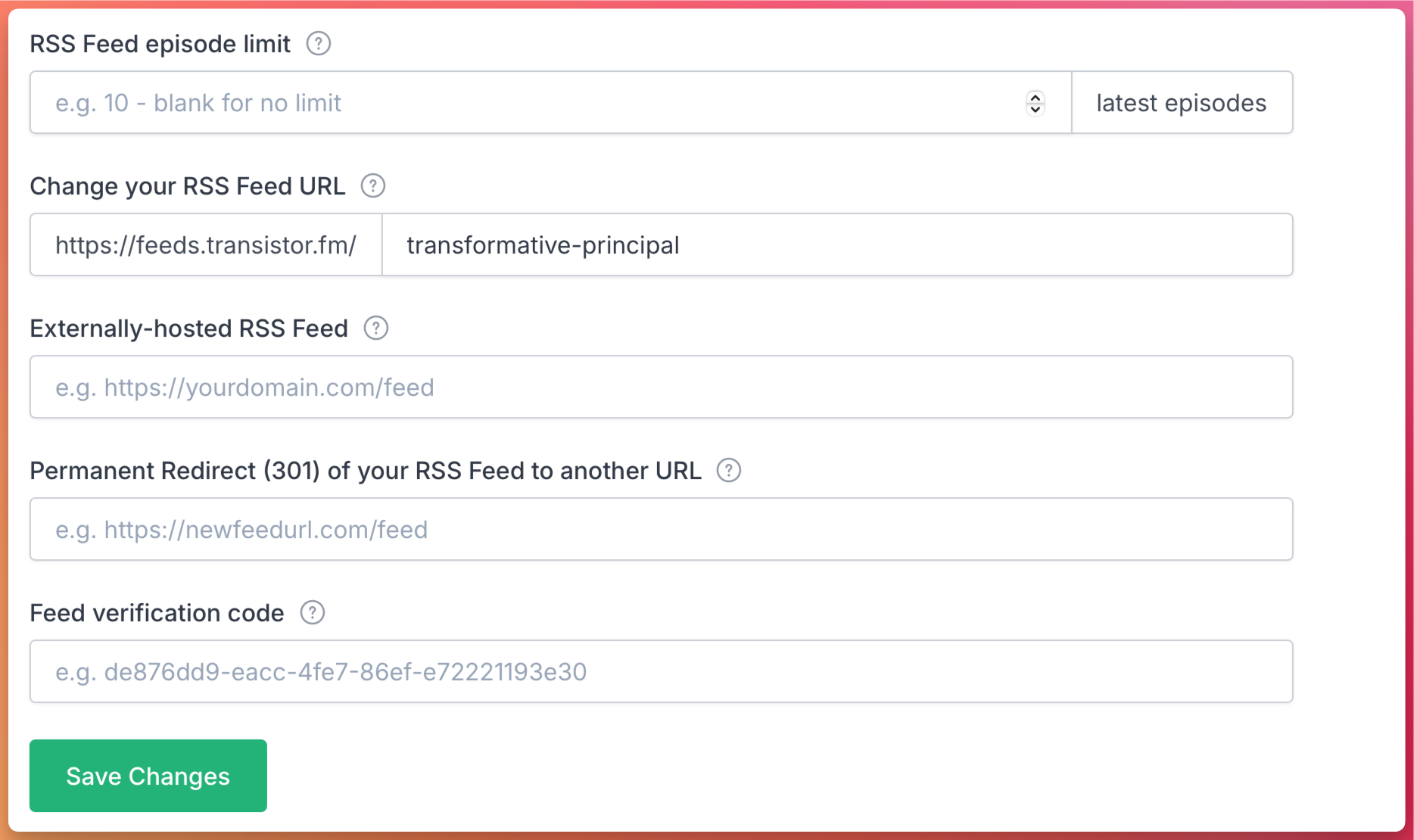
Transistor makes it really easy to bring a podcast over. They have a great interface that allows you use either the Apple Podcasts listing, just by searching for the name, or you can plug in the RSS feed.
For this particular show, Transistor even warned me something wasn’t right.

Your RSS Feed contains exactly 300 episodes, which may indicate that thee feed is limited to the 300 latest episodes. If that number looks correct, please continue. Otherwise, remove the feed limit from your current podcast host and restart the import process.
BlogTalkRadio doesn’t have a button I can click or a field I can enter to change that, so I reached out to support.
Transistor makes this really easy, and this is also the place where you can update the new feed when you leave Transistor.
Unfortunately, BlogTalkRadio doesn’t have a good helpdesk section on this topic, and I can’t find anything on my multiple google searches.
The best I could find is that BluBrry offers a helpdesk article on this topic, but here’s the crazy thing: according to Blubrry, BlogTalkRadio does not offer a 301 redirect. I got a whiff of this from their announcement:
we do want to let you know about our sister company Spreaker, where we can place an easy redirect to ensure the safety of your podcast. We can also offer a great discount if you are interested in any of the available plans. Via Podnews
This is reprehensible that they don’t offer a 301 redirect.
Why is a 301 Redirect important?
A 301 redirect makes it so your audience follows you to the new platform. Without a proper 301 redirect, you will have to build your audience from scratch.
For example, the Blubrry help article suggests this:
Unfortunately, Blog Talk Radio does not give you a way to do a 301 redirect of your podcast feed away from their service. The best way to keep most of your subscribers to do the following: Resubmit your NEW podcast feed to iTunes using a slightly different name (to be changed back after it’s approved). 30 days before you quit uploading to Blog Talk Radio, record two versions of your podcast episodes: one normal and one that you will have an announcement at the beginning of the show that says, “If you are hearing this, you will not receive the new episodes after xxx date. I am moving the feed and the new feed is available at
.” Make sure you have your RSS feed available on your website and/or in your post for each episode. Also put the announcement at the end of the podcast episode.
This kind of behavior really frustrates me. It’s hostile to the user and not fair to those who don’t understand how this technology works.
To be a successful podcaster, you shouldn’t have to know all the details, because you should be able to trust the companies that are making these products available!
This is the kind of lock-in that has no place on the open web. See Don’t Call it a Substack.
I’ll update this as the process continues.
How to remove the Feed Limit in BlogTalkRadio Podcast Feeds
Updated November 23, 2024
Today, BlogTalkRadio shared that if you replace the www with beta in your podcast feed, it will come over.
- Replace the `www.` in your BlogTalkRadio RSS feed URL https://www.blogtalkradio.com/YourShowName/podcast with `beta.`
For example, your updated RSS feed would look like this:
`https://beta.blogtalkradio.com/YourShowName/podcast
Unfortunately, this brought all the episodes over but it did not include any audio files, as “- 2000 Episodes [were] missing an audio file or have an unreachable audio file URL.”
Update November 25, 2024
After not hearing back from blogtalkradio, I decided to set up a failsafe. Rather than working on things I should be, I decided to dive into this little rabbit hole.
DownThemAll
One of my favorite extensions for Chrome is this tool called DownThemAll which helps you download loads of files from a site.
The backend admin view allows you to view 25 posts at a time. This podcast has 4025 episodes! So how are we going to get them all?
Well, there are 165 pages of posts, so I’m just going to download them all!
Filenames. The first issue I ran into is that the filenames were downloaded as gibberish! They had filenames like:
566bb652-54f7-5ac7-b1dd-50b0d4d05fa2.mp3
After some fiddling, I changed the “mask” to download the files and rename them like so:
edutalk-2011-04-25.mp3
This included the name of the show, followed by the date it was released.
Mp3 files contain data in them, called ID3 tags. This includes the Title. Just having the date wouldn’t help me as much, so I needed to do some adjusting to match it with the right episode.
I turned to my old pal Hazel to fix this problem.
Hazel is a tool that will rename files based on certain rules that you set up. I wrote my first book about being a paperless principal and used Hazel extensively in my day-to-day work.
I told Hazel to go through those files and pull out the word edutalk and add the Title tag from Spotlight, which led to filenames like this:
2011-04-25-SCHOOL BOARDS UPDATE.mp3
Hazel can even make it so that title case is followed, instead of being in all caps:
2011-04-25-School Boards Update.mp3
I don’t really care about that, so I didn’t bother, but I could if I wanted to.
Scraping
Worried that I might not be able to get all this content out. I decided to create a scraper of the web site.
I have no idea how to do that, but in building this site, I’ve learned a few things about Ruby, and I figured this could be a job for Ruby.
So, I booted up ChatGPT and asked it to make me a scraper.
Here’s the whole chat Transcript. I’ve got to say, this is amazing that I can do this.
I copied the script from ChatGPT and pasted it in BBEdit, my editor of choice, and saved it in a folder called Scraper, then went to Terminal and had it run the script for me using:
ruby scraper.rb
And then I suddenly had a folder full of markdown files to make it easy to get the content where I need it in Transistor.
Naturally I ran into a few problems with filenames being too long, filenames not being what I needed, redirects happening, and more, but I was able to continue working to fix them with the help of ChatGPT.
The pages are structured like this:
https://www.blogtalkradio.com/edutalk/410
So this page 410 is the last page. There’s no page 411.
I told ChatGPT how it’s structured and it gave me a new code. There were several iterations, and while researching I learned about this site that explains how to code it by hand.
As far as learning goes, the tutorial certainly gives me a better understanding of what I need to do. But the challenge is that it was so much faster to go back and forth with ChatGPT.
This makes the idea of learning so deep! There’s so much that we still don’t understand about how to learn most effectively. If I didn’t have ChatGPT, I would have used the tutorial, but since I did, I just kept telling it where it went wrong.
In all, it took about 2 hours of working on this to make it happen with some sidetracks in there. Once the script was running effectively, it took about 8 minutes to pull all the content down from the site.
As a cool bonus, while there is a page 411, it just doesn’t have any episodes on it, the ruby script was programmed by ChatGPT to stop after 410 pages. That’s awesome.
It did create about 4000 extra undated files that were the page navigation, play now, links, more.
What I probably should have done is saved this as a github project and updated it each time I made some changes. That would have been better, I’m sure. I’ll get there, someday.
Here’s what I don’t know how to do, yet. How do I make these things work on the web? As in, how do I make an application on that I will be able to use, and potentially provide as a service to others? Should I learn to code?
I realized downloading them all by hand would be a pain, even if it was 25 at a time. That would still mean I need to download 165 sessions. So I had ChatGPT build a scraper for the MP3s. That ran for about 3.5 and then timed out with a TCPS Socket error. I don’t know what that means, but quite the eventful day today!
Could have been because my computer went to sleep, finally.
Update December 8, 2024
The blog is now totally transferred over. They were able to do it all on the backend and make it work! Wahoo! Check it out here